Ranking Methodology
General
Authority's rankings use objective data to quantify nearly every college in the United States.
Our Comprehensive Approach
The Selections
Addressing Subjectivity
Mathematical Methods
Always the authority
Our Methodology
General Rankings
At Authority, simplicity and transparency are fundamental. College decisions shape an important life transition in a young student's life, and deciding what college to attend or which major to study can be a confusing and high pressure journey.
Post-secondary institutions themselves can feel pressure too; declines in state and federal funding over the last few decades have forced colleges to function more like businesses trying to succeed.
With the prosperity of both the student and the institution weighing on the college decision, the information out there can not only be overwhelming, but confusing as well.
Our Goal
Our goal is to make the process easy to understand with objective data and clear explanations so students can make informed college decisions.
The foundations of our ranking methodology are objectivity and directness. We strive to present information in a clear and understandable way, allowing you to make your own decisions.
We have rated nearly every college in the United States and rated the best colleges for every major.
Rankings
We have rankings detailing colleges with the best professors, the highest earning graduates, and even the colleges with the best student life. The general methodology detailed here serves as our framework for establishing data driven rankings for many facets of collegiate life.
"At Authority, simplicity and transparency are fundamental."
Driven by validity
Regarding Subjectivity
Subjectivity in our Methodology
There are thousands of data points for every college in the country. To create a useful ranking out of all that data, the relevance of each data point must be assessed.
The Authority ranking takes inspiration from how the government ranks colleges, how private industry ranks colleges, and from our own lived experiences as recent and not-so-recent college students.
From this work clearly relevant metrics emerged. Assessing the proportional relevance of each metric brought to reality the most effective metrics to objectively rate colleges.
"There are thousands of data points for every college in the country."
The right data
Our Picks
The Selections
Contributors to the rankings included data such as:
- 6 Year Graduation Rate - the percentage of students who complete their degree within 6 years of enrollment;
- Student to Faculty Ratio - correlated with student success represented by the number of students for every one instructor;
- Retention Rate - which functions as a comprehensive measure of student satisfaction with the college.
While subjective information is essential to the college decision, we did not include purely subjective data such as school colors.
"While subjective data is essential to the college decision, such data was excluded from our criteria"
We did the math
Mathematical Methods
After selecting the relevant data points for each ranking, the data needed to be normalized and combined into composite indices to generate a score for every college. Below are several methods we attempted to implement:
Z-score
Z-score normalization becomes an improper method with skewed data sets, and many of our metrics, by virtue of being real world data, demonstrate significant skew. It was deemed improper to use z-score normalization as outliers for any single metric had a disproportionate effect on the overall score.
Instead, min-max feature scaling was the most effective way to compare and weight metrics on very different scales from datasets with different skews.

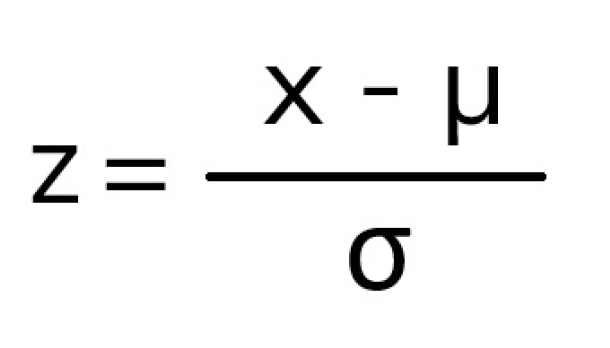
Min-Max Feature Scaling
To explain min-max feature scaling, let's consider a theoretical ranking based exclusively on endowment and acceptance rate, i.e. 'Best Colleges for 1%ers'. In this imaginary ranking, 80% of the total ranking is based on endowment and the other 20% is based on acceptance rate. First, both fields are normalized on a 0 to 1 scale. The college with the lowest acceptance rate would get a score of 1; the school with the highest endowment would get a score of 1. The individual scores are then multiplied by their respective weights to create a composite score.
The final normalization is for clarity. Each composite index is graded with a score out of 100 again using min-max scaling. This places all schools on an equivalent and simple to understand scale. Sticking with min-max feature scaling for this normalization keeps the data linear, rather than placing undue emphasis on the best and worst performers.
Finally, if the '1%ers' score were to be used as a component of a new composite ranking it would again be normalized from 0-1 using min-max feature scaling.
Not all data can be ranked on a simple linear scale, therefore min-max feature scaling does not work for all data. For example, Simpson's Diversity Index is used in creating Authority's diversity indices. Simpson's Diversity Index is ideal for measuring diversity of varied populations, and it was used to normalize these attributes for use in composite scores.
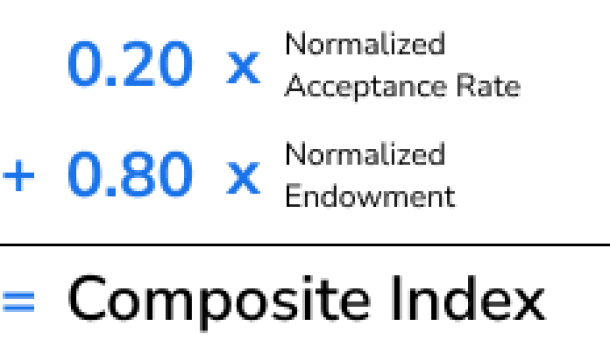
Simpson Diversity Index
The rankings produced by combining these methodologies accurately reflect the positioning of all colleges in the United States. You may notice that keeping the data linear draws less stark differences between individual college rankings, this is by design.
Many colleges provide very similar experiences which is a great thing! The comparable similarity between schools means that a student one can choose where to attend based on personal characteristics that cannot and should not be quantified by an objective ranking.
If a student really wants to be within driving distance of the ocean, they should not needlessly feel like they have to choose between their own happiness and a better educational experience. All told, many colleges are quite alike.
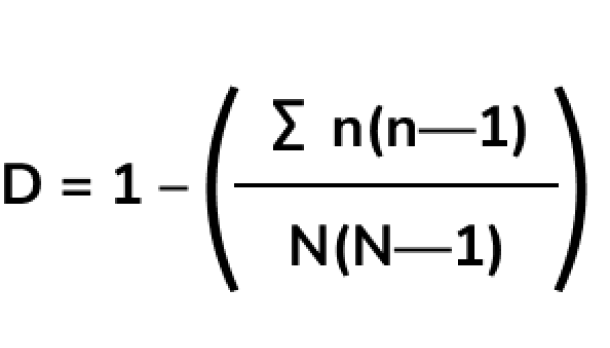
We filled in the blanks
Imputation
Addressing Missing Values
Mean imputation was used for individual missing data points for a college. For example, many colleges only ask for one standardized test score, ACT or SAT, and so cannot submit data for tests they do not collect.
Colleges that did not submit ACT scores, or any other piece of information, were assigned the national average score for that data. If a college was missing 50% or more of the data used in calculations, or where total student enrollment was less than 300 students, that college was eliminated from the rankings.
Obviously if a school is missing a substantial amount of data, imputation for the missing data stops actually representing the college. If a school has a very small enrollment the law of large numbers stops applying to a student body that has less than 75 students a year.
Data Sources
Data Sources
Data Sources
The majority of the data used in calculations comes from two main government data sources, the National Center for Education Statistics (NCES) and the Bureau of Labor Statistics.
The NCES creates a large-scale self-report survey of postsecondary institutions in the United States called the Integrated Postsecondary Education Data System (IPEDS). IPEDS specifically was used for the majority of academic and financial ranking.
Post-college data came from the Bureau of Labor Statistics institution-linked employment data. A more in-depth look at Authority's data sources can be found here.